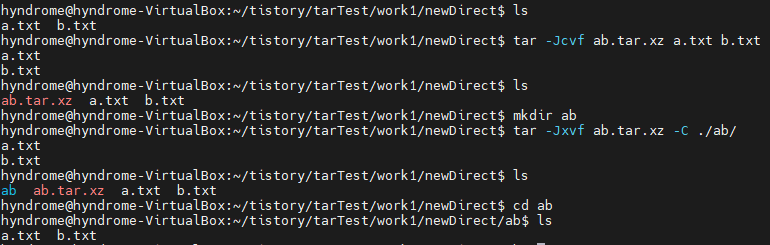
기본문법
Target 타켓
목표 파일 이름, 빌드하려는 최종 결과물
1개 이상의 타겟이 있어야 한다
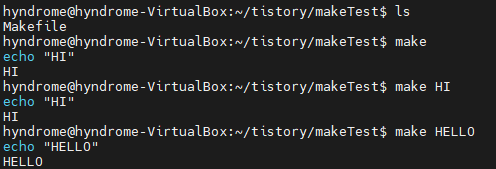
comment를 실행하며 comment 앞은 반드시 Tab 들여쓰기를 해야한다 (그림에서 노란색으로 표시된 곳)
HI:
echo "HI"
HELLO:
echo "HELLO"
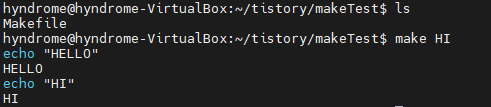
Dependency 의존성
Target을 생성하기 위한 파일 목록
의존성 Target을 먼저 수행하게 됨
아래의 경우 HI 를 실행하면 의존성에 HELLO가 있어서
HELLO를 우선 실행하게 된다
HI: HELLO
echo "HI"
HELLO:
echo "HELLO"
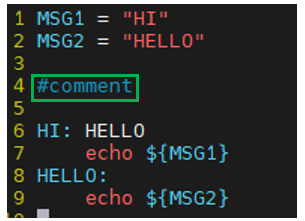
Variable 변수
앞에 $를 붙이고 소괄호 () or 중괄호 {} 를 붙여서 사용한다.
가독성을 위하여 script 최상단에 작성
MSG1 = "HI"
MSG2 = "HELLO"
HI: HELLO
echo ${MSG1}
HELLO:
echo $(MSG2)
Comment 주석
# 을 사용하여 주석을 표시한다.
한줄 주석만 지원한다.
특수변수 (자동변수)
$@ : Target 이름
$^ : Dependecy 목록 전체
$< : Dependecy 목록 중 첫 번째
...
연산자
다양한 연산자를 갖는다
+=
:= (simple equl)
= (reculsive equl)
단계별 Makefile 제작
함수 2개가 있는 makefile을 단계별로 제작해보자
common.h
#include <stdio.h>func1.h
void func1();func1.c
1 #include "common.h"
2
3 void func1()
4 {
5 printf("Func1\n");
6 }func2.h
void func2();func2.c
#include "common.h"
void func2()
{
printf("Func2\n");
}main.c
#include "common.h"
#include "func1.h"
#include "func2.h"
int main()
{
printf("main start!\n");
func1();
func2();
printf("main end!\n");
return 0;
}
Makefile 1단계
파일 구성을 바탕으로 dependencies를 작성한다
result: main.o func1.o func2.o
gcc main.o func1.o func2.o -o result
main.o: main.c common.h func1.h func2.h
gcc -c main.c
func1.o: func1.c common.h func1.h
gcc -c func1.c
func2.o: func2.c common.h func2.h
gcc -c func2.c
clean:
rm -r ./*.o result
Makefile 2단계 - 변수 추가
CC: compiler가 바뀔 때 변경
OBJS: 목적 파일 목록
CC = gcc
OBJS = main.o func1.o func2.o
result: $(OBJS)
$(CC) -o result $(OBJS)
main.o: main.c common.h func1.h func2.h
$(CC) -c main.c
func1.o: func1.c common.h func1.h
$(CC) -c func1.c
func2.o: func2.c common.h func2.h
$(CC) -c func2.c
clean:
rm -r $(OBJS) result
Makfile 3단계 - 특수 변수 추가
$@ : Target을 나타냄
$^ : 의존성 타겟들을 나타냄
$< : 의존 타겟 중 첫번째
CC = gcc
OBJS = main.o func1.o func2.o
result: $(OBJS)
$(CC) -o $@ $^
main.o: main.c common.h func1.h func2.h
$(CC) -c $<
func1.o: func1.c common.h func1.h
$(CC) -c $<
func2.o: func2.c common.h func2.h
$(CC) -c $<
clean:
rm -r $(OBJS) result
Makefile 4단계 - 컴파일러 옵션 변수 추가
컴파일 옵션 지정 $(CFLAG)
-g : 디버깅 (Trace) 가능하도록 설정
-Wall : Warning이 뜨면 Error 처럼 멈추도록 함
-O2 : 최적화 2단계 옵션
CC = gcc
CFLAG = -g -Wall -O2
OBJS = main.o func1.o func2.o
result: $(OBJS)
$(CC) $(CFLAG) -o $@ $^
main.o: main.c common.h func1.h func2.h
$(CC) $(CFLAG) -c $<
func1.o: func1.c common.h func1.h
$(CC) $(CFLAG) -c $<
func2.o: func2.c common.h func2.h
$(CC) $(CFLAG) -c $<
clean:
rm -r $(OBJS) result
Makefile 5단계 - wildcard, 확장자 치환 적용
wildcard 함수
지정된 패턴에 해당하는 파일 목록 갖고오기
*.c : 현재 디렉토리 내 모든 .c 파일 가져오기
확장자 치환 사용
변수에 할당된 파일 목록에서 확장자 치환
변수명:[pattern]=[replacement]
SRCS의 .c를 .o 변경해서 OBJS에 저장
CC = gcc
CFLAG = -g -Wall -O2
SRCS = $(wildcard *.c)
OBJS = $(SRCS:.c=.o)
result: $(OBJS)
$(CC) $(CFLAG) -o $@ $^
main.o: main.c common.h func1.h func2.h
$(CC) $(CFLAG) -c $<
func1.o: func1.c common.h func1.h
$(CC) $(CFLAG) -c $<
func2.o: func2.c common.h func2.h
$(CC) $(CFLAG) -c $<
clean:
rm -r $(OBJS) result
Makefile 6단계 - makedepend 유틸리티 및 SUFFIXES 적용
makedepend
입력한 .c 파일을 분석해서 의존성 헤더파일을 등록해주는 make 도우미 유틸리티
makedepend 설치
sudo apt install xutils-dev -ymakedepend 실행
makedepend main.c func1.c func2.c -Y
Makefile 하단에 의존성 목록이 자동으로 추가된 것을 확인할 수 있다.
makedepend 적용
makedepend Target 추가
SUFFIXES
파일 확장자와 관련된 규칙을 지정할 때 사용
.c파일을 .o 파일로 컴파일하는 것을 뜻함 (default)
suffixes 뜻은 접미사로 확장자를 뜻함
.c .o
.c 파일을 .o 파일로 변환할 때 실행할 명령을 정의
CC = gcc
CFLAG = -g -Wall -O2
SRCS = $(wildcard *.c)
OBJS = $(SRCS:.c=.o)
SUFFIXES = .c .o
result: $(OBJS)
$(CC) $(CFLAG) -o $@ $^
.c .o:
$(CC) $(CFLAG) -c $<
clean:
rm -r $(OBJS) result
depend:
makedepend $(OBJS) -Y
실행
make depend
make
Makefile 7단계 - 파일명 매크로 추가
all
.c .o: 는 default 값이라서 생략 가능
CC = gcc
CFLAG = -g -Wall -O2
SRCS = $(wildcard *.c)
OBJS = $(SRCS:.c=.o)
SUFFIXES = .c .o
TARGET = result
all: $(OBJS)
$(CC) $(CFLAG) -o $(TARGET) $^
clean:
rm -r $(OBJS) $(TARGET)
depend:
makedepend $(OBJS) -Y